How to disable automatic creation of the robots.txt file
By default, on shared and reseller servers, if a robots.txt file does not exist in the document root (public_html) directory, the server automatically creates a new robots.txt file at midnight.
This article describes how to disable this behavior. You may want to do this, for example, if you do not need to specify how search engines and web crawlers index your site.
Table of Contents
Disabling automatic generation of the robots.txt file
To prevent the server from automatically generating a robots.txt file in the document root directory, follow these steps:
- Log in to cPanel.If you do not know how to log in to your cPanel account, please see this article.
- In the FILES section of the cPanel home screen, click the File Manager icon:

- In the left sidebar, click the public_html folder.
On the top menu bar, click + File:
In the New File dialog box, in the New File Name text box, type robots.txt.ignore:
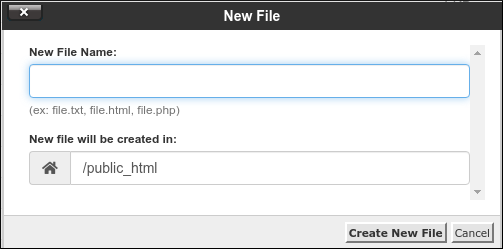
- Confirm that the New file will be created in text box is set to /public_html.
- Click Create New File. Automatic generation of the robots.txt file is now disabled.
More Information
For more information about the robots.txt file, please vist http://www.robotstxt.org.
Article Details
- Level: Beginner
Grow Your Web Business
Subscribe to receive weekly cutting edge tips, strategies, and news you need to grow your web business.
No charge. Unsubscribe anytime.
Did you find this article helpful? Then you'll love our support. Experience the A2 Hosting difference today and get a pre-secured, pre-optimized website. Check out our web hosting plans today.